켤레 사전 분포처럼 분포함수 간에 관계가 있거나 함수가 간단한 형태의 경우 적분을 쉽게 할 수 있다. 하지만 복잡한 함수 형태이거나 high dimension인 경우 Monte carlo integration이나 numerical method를 이용한 적분 방법을 적용하기 힘들다. 이 때 사용하는 방법이 Markov chain Monte Carlo 방법이다.
Monte Carlo integration의 경우 independence sample을 뽑는데 high dimension인 경우 independence sample을 뽑는 것이 어렵다. 따라서 dependence sample을 뽑아서 이 문제를 해결해보자는 것이 Markov Chain Monte Carlo(MCMC)의 아이디어이다. 앞에 Markov Chain이 붙은 것은 dependence sample을 Markov Chain 구조에서 뽑기 때문이다. 이상적인 Markov Chain의 경우 특정 정칙 조건을 만족해야한다.
regularity conditions
irreducibility
positive recurrence
aperiodicity
Metopolis-Hasting algorithm
Markov Chain을 따르는 \(X\)를 발생시키기 위해서는 regularity conditions을 만족해야 한다. 일반적으로 target distribution과 같은 support set을 갖는 proposal distribution의 경우 regularity conditions를 만족한다. proposal distribution이 regularity condition을 만족하는 경우 Metropolis-Hastings chain의 stationary distribution은 taget distribution이 된다.
target distribution과 support set이 같은 임의의 proposal distribution \(g(\cdot|X_t)\)를 선정한다.
\(g(\cdot|X_t)\)에서 초기값 \(X_0\)를 생성한다.
chain이 정상 분포로 수렴할 때까지 다음의 과정을 반복한다.
\(g(\cdot|X_t)\)로부터 \(Y\)를 발생시킨다.
\(U(0,1)\)에서 random number \(U\)를 발생시킨다.
If \(U\le r(X_t, Y) = \frac{f(Y)g(X_t|Y)}{f(X_t)g(Y|X_t)}\)\(Y\)를 채택, \(X_{t+1}=Y\) otherwise \(X_{t+1}=X_t\)
Increment t
Example
Metropolis-Hasting algorithm을 이용해서 Rayleigh 분포에서 표본을 추출하기 해보자.
\(X_t\)=x[i-1], If \(U\le \frac{f(Y)g(X_t|Y)}{f(X_t)g(Y|X_t)}\)\(Y\)를 채택, \(X_{t+1}=Y\) otherwise \(X_{t+1}=X_t\)\(X_t+1\)을 x[i]에 저장한다.
Increment t
\(Y\)가 accept 될 확률은 다음과 같다. \(\alpha (X_t, Y) = min(1, \frac{f(Y)g(X_t|Y)}{f(X_t)g(Y|X_t)})\)
rayleigh <-function(x, sigma){return ((x/sigma^2)*exp(-x^2/(2*sigma^2))) # Rayleigh distribution를 함수로 정의}m <-10000sigma <-4x <-numeric(m)x[1] <-rchisq(1, df =1) # initial value k <-0u <-runif(m) # generate u from U(0,1)for (i in2:m) { xt <- x[i-1] y <-rchisq(1, df = xt) num <-rayleigh(y, sigma)*dchisq(xt, df = y) # posterior theta t den <-rayleigh(xt, sigma)*dchisq(y, df = xt) # posterior theta t-1if (u[i] <= num/den) { x[i] <- y # accept }else { x[i] <- xt # reject k <- k+1 }}k # reject된 갯수
[1] 4000
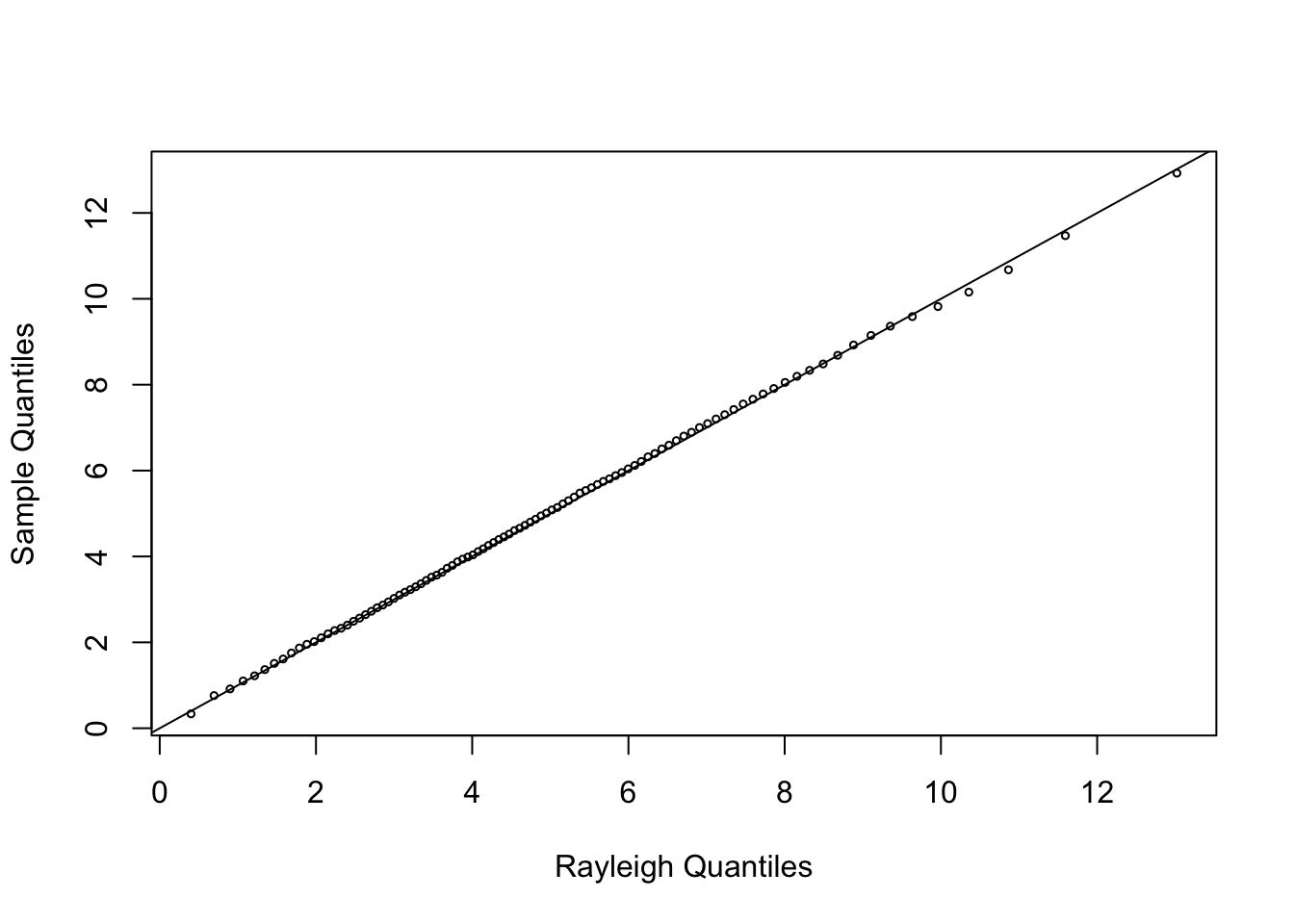
실제 Rayleigh 분포와 같은지를 비교하기 위해 QQplot을 그리면 다음과 같다.
b <-2001y <- x[b:m]a <-ppoints(100)QR <- sigma*sqrt(-2*log(1-a))Q <-quantile(y, a)qqplot(QR, Q, main ='', cex =0.5, xlab ='Rayleigh Quantiles', ylab ='Sample Quantiles')abline(0,1)
proposal distribution을 gamma distribution으로 변경할 경우 다음과 같다.
Metropolis Sampler
Matropolis Hastings sampler는 Metropolis sampler의 일반화이다. Metropolis sampler는 Metropolis algorithm에서 proposal distribution이 symmetric일 때를 의미한다.
proposal distribution이 symmetric이므로
\(g(X|Y) = g(Y|X)\)
를 만족한다.
따라서 기존의 Metropolis Hastings sampler 식은 조건부 분포 \(g\)가 약분되므로 식이 간소화된다. \(r(X_t, Y) = \frac{f(Y)g(X_t|Y)}{f(X_t)g(Y|X_t)} = \frac{f(Y)}{f(X_t)}\)
Random Walk Metropolis
Random Walk Metropolis sampler는 Metropolis Sampler의 special case이다. proposal distribution은 symmetric이며, \(g(Y|X_t) = g(X_t - Y)\)로 정의한다.
random increment \(Z\)를 \(g(\cdot)\)로 부터 발생시킨다.
\(Y=X_t+Z\) 로 정의한다.
\(r(X_t, Y) = \frac{f(Y)}{f(X_t)}\)를 계산한다.
target distribution과 support set이 같은 임의의 proposal distribution \(g(\cdot|X_t)\)를 선정한다. proposal distribution은 symmetric이며, \(g(Y|X_t) = g(X_t - Y)\)로 정의한다.
random increment \(Z\)를 \(g(\cdot)\)로 부터 발생시키고, \(Y=X_t+Z\) 로 정의한다.
chain이 정상 분포로 수렴할 때까지 다음의 과정을 반복한다.
\(r(X_t, Y) = \frac{f(Y)}{f(X_t)}\)를 계산한다.
\(U(0,1)\)에서 random number \(U\)를 발생시킨다.
If \(U\le r(X_t, Y) = \frac{f(Y)g(X_t|Y)}{f(X_t)g(Y|X_t)}\)\(Y\)를 채택, \(X_{t+1}=Y\) otherwise \(X_{t+1}=X_t\)
Increment t
independence sampler
independence sampler는 Metropolis Hastings Sampler의 special case이다. independence sampler에서 proposal distribution은 다음과 같이 정의된다.
\(g(Y|X_t) = g(Y)\)
즉, independence sampler는 chain의 이전 값에 의존하지 않는다.
independence sampler는 proposal density가 target density에 가깝게 match될 경우에 잘 동작한다. 하지만 이러한 경우는 거의 없으며, independence sampler는 잘 동작하지 않는 경우가 많다. 따라서 단독으로 쓰이는 경우는 없으며, 보통 hybrid MCMC method에서 사용한다.
Gibbs sampler
Gibbs sampler도 Metropolis Hastings Sampler의 special case이다. target distribution이 multivariate distribution일 때 주로 적용한다. Gibbs sampler는 일변량 조건부 분포를 계산할 수 있고, 쉽게 simulation이 가능한 경우에 사용할 수 있다.
Gibbs sampling의 목적은 conditional pdf로 모르는 형태의 joint pdf와 marginal pdf를 구하는 것이다. 따라서 \(f(x,y)\)는 실제로는 beta-binomial 분포로 구할 수 있지만 gibbs sampling을 위해서 \(f(x,y)\)를 모르고 \(f(x|y)\)와 \(f(y|x)\)는 안다고 가정한다.