library(tidyverse)
library(factoextra)Silhouette coefficient
실루엣 계수는 아래와 같은 순서로 계산됩니다. 순서대로 살펴보겠습니다.

- \(i\) 번째 관측치가 속해있는 군집 내에 average dissimilarity \(a_i\) 를 계산
\[ \begin{aligned} a(i) &= \frac{1}{|C_I| - 1} \sum_{j \in C_I, i \not= j} d(i, j) \\ where \quad &C_I : \text{I 관측치가 속해있는 군집 내 관측치의 수} \\ & d(i, j) : \text{i, j 사이의 거리(유클리디안 or 맨하탄 등등)} \end{aligned} \]
\(a_i\)는 compactness를 의미합니다(그림. 빨간선). 즉, 군집 내 밀도가 얼마나 높은지(군집 내 분산이 작은지)를 의미합니다. 단순히 잘 분리된 군집을 생각해보면 군집 내 밀도가 높을수록 잘 된 군집이라고 볼 수 있습니다. 따라서 \(a_i\)는 작을수록 좋습니다.
- \(i\) 번째 관측치가 속해있지 않은 군집에 대해서 \(b_i\) 를 계산
\[ \begin{aligned} b(i) &= \min_{J \not = I} \frac{1}{|C_J|} \sum_{j \in C_J} d(i, j) \\ where \quad &C_J : \text{j 관측치가 속해있는 군집 내 관측치의 수} \\ & d(i, j) : \text{i, j 사이의 거리(유클리디안 or 맨하탄 등등)} \end{aligned} \]
\(b_i\)는 seperation을 의미합니다(그림. 파란선). 즉, 군집 간 얼마나 멀리 떨어져있는지를 의미합니다. 단순히 잘 분리된 군집을 생각해보면 군집 간 거리가 멀수록 잘된 군집이라고 볼 수 있습니다. 따라서 \(b_i\)는 클수록 좋습니다.
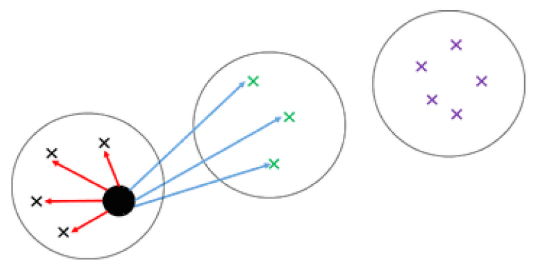
- \(i\) 번째 관측치에 대해서 실루엣 계수 \(S_i\) 계산
\[ \begin{aligned} S(i) &= \frac{b(i) - a(i)}{\max(a(i), b(i))}, \quad -1 \le S(i) \le 1 \end{aligned} \]
\(S(i)\)는 분모를 생략하면 \(b(i) - a(i)\)로 계산됩니다. \(a_i\)는 작을수록 좋고, \(b_i\)는 클수록 좋으므로, \(b(i) - a(i)\)는 클수록 좋습니다. 최대값은 \(1\)이 됩니다.
Average silhouette method
Average silhouette method에 대해 알아보겠습니다. 알고리즘의 대략적인 순서는 다음과 같습니다.

여기서 avg.sil은 위에서 구한 실루엣 계수의 평균을 의미합니다. 즉, 각 관측치별로 \(S(i)\)를 구하고, 평균을 취하면 avg.sil을 구할 수 있습니다.
Example
df_iris <- scale(iris[, -5])fviz_nbclust(df_iris, kmeans, method = "silhouette")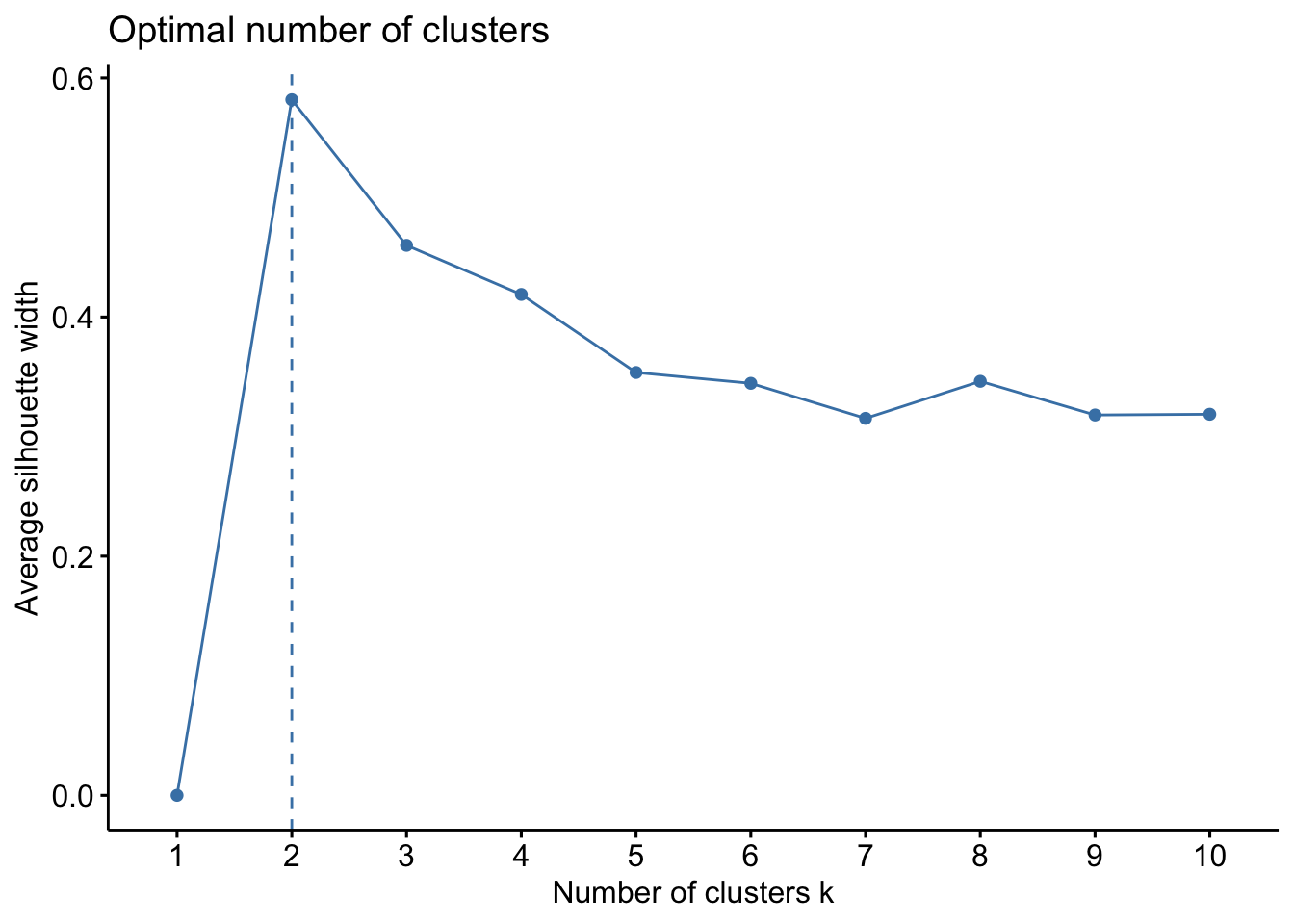
fviz_nbclust()에서는 avg.sil이 가장 높은 \(k\)를 최적의 \(k\)값으로 선정합니다.
km.res2 <- df_iris %>%
eclust("kmeans", k = 3, graph = F, nstart = 25)
fviz_silhouette(km.res2) cluster size ave.sil.width
1 1 50 0.64
2 2 53 0.39
3 3 47 0.35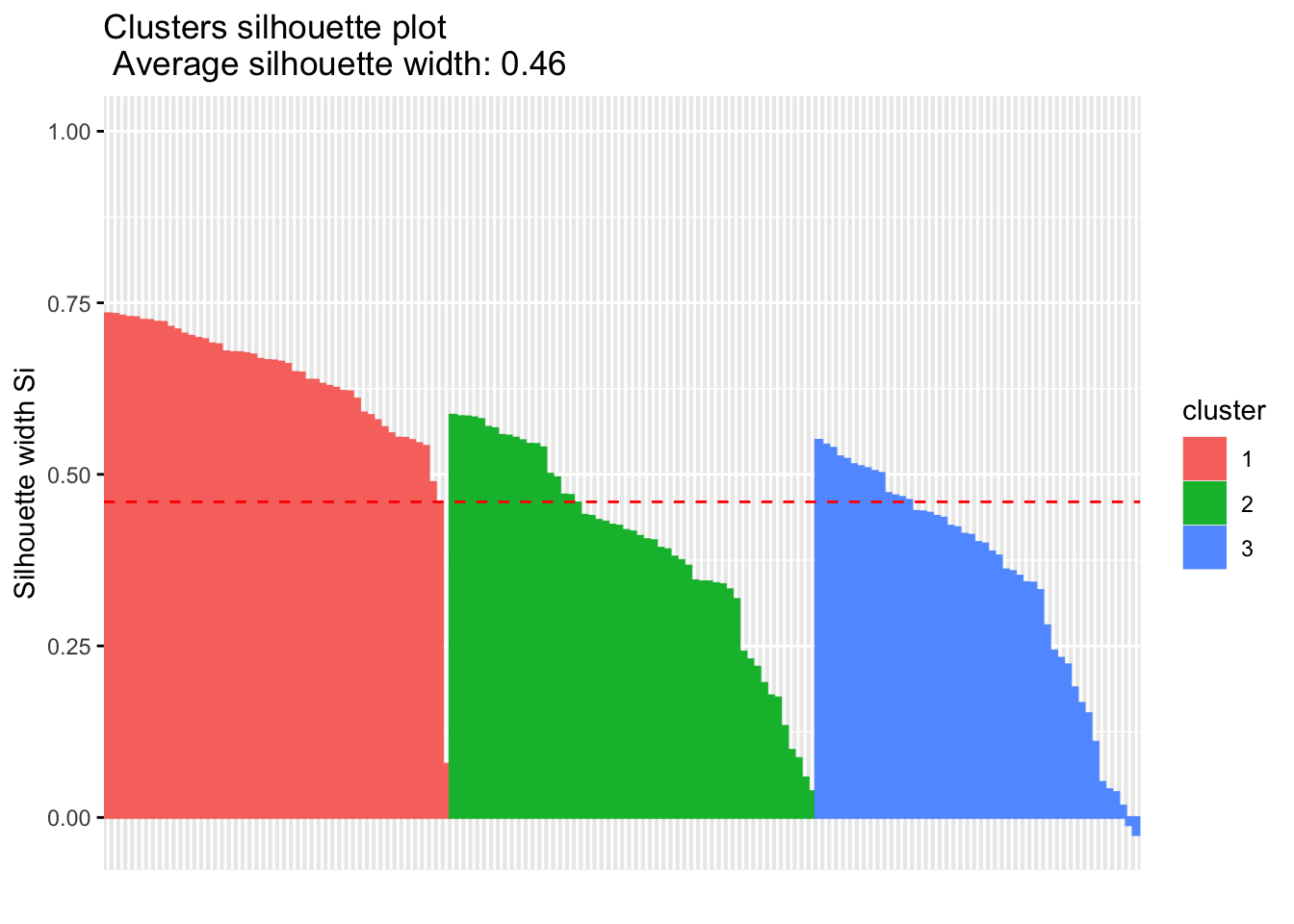
silhouette plot을 보면 빨간 점선으로 avg.sil이 표시되는 것을 볼 수 있습니다. 각 군집별 ave.sil.width를 평균내면 avg.sil과 같습니다. 오른쪽 끝에 실루엣 계수 값이 음수인 경우가 보입니다. 실루엣 계수가 음수라는 의미는 \(a(i) > b(i)\) 라는 의미이므로, 관측치가 잘못된 군집에 할당되었다는 의미로 볼 수 있습니다.
sil <- km.res2$silinfo$widths[, 1:3]
neg_sil <- which(sil[, "sil_width"] < 0)
sil[neg_sil, ] cluster neighbor sil_width
112 3 2 -0.01058434
128 3 2 -0.02489394해당 관측치를 뽑아보면 112, 128번 index의 관측치인 것을 확인할 수 있습니다.
Warning
silhouette coefficient는 각 관측치별로 계산해야 하기 때문에 계산량이 많습니다. 데이터가 클 때는 주의가 필요합니다.
참고자료
https://en.wikipedia.org/wiki/Silhouette_(clustering)
https://www.datanovia.com/en/wp-content/uploads/dn-tutorials/book-preview/clustering_en_preview.pdf
Citation
BibTeX citation:
@online{don2022,
author = {Don, Don and Don, Don},
title = {Average Silhouette Method},
date = {2022-10-08},
url = {https://dondonkim.netlify.app/posts/2022-10-08-sillouette/silhouette.html},
langid = {en}
}
For attribution, please cite this work as:
Don, Don, and Don Don. 2022. “Average Silhouette Method.”
October 8, 2022. https://dondonkim.netlify.app/posts/2022-10-08-sillouette/silhouette.html.